Transform Your Table with a Materialized View
Part 3 of x of Sporting Stylish SQL with Stephen
Note: this was published originally on Medium in August 2019
In our previous projects, we created a table and an upload process for our Premier League results data, but now our manager tells us she is looking at the data we have and wants to know the answer to the operative question: Who does the Premier League table look like now?
Now, you might be looking at me wondering, “I’m new here, what’s she talking about? What in tarnation does a Premier League table even look like?” Never fear, we are going to get through this together:
That City, they’re pretty good, huh?
Behold, the Premier League table for the 2017/2018 season.
The Premier League rules state that a team’s rank is based on the following factors in descending order of importance:
Points: Three points for a win plus one point for a draw
Goal Difference: Goals For minus Goals Against
Goals For
How do we take the data we have already in our xpert.england_view and use it to build this League Table? Let’s start by taking a look at a specific game. I’ll close my eyes and pick a game out of the hat…Wolverhampton vs Leicester City:

Real best of the rest game here
By my calculations, the columns in the above query are what we need to get the points, goal difference and goals scored for each team. When you really think about it, this game by itself actually represents two results in which we are interested: one, a loss for Leicester and the other, a win for Wolves — one game, two results. To represent them properly, we’re going to have to turn this one-row-per-game data, into two rows, one row per team result.
Let’s use the Wolves Leicester game as our working set, we’ll turn it into a CTE called ws. When you are exploring the data and building your queries, I find it useful to start with a small(er) working set, enough for you to see the changes you’re trying to make as you shape your query. It makes it easier to see what’s happening at a granular level, it taxes the database much less and when you’re done building whatever it is you’re building you can just unceremoniously get rid of it.
Now that we have a working set, what transformations do we want to perform upon it? Well, like I said, we’re trying to convert one row into two, so it sounds like we could use a UNION to stack our teams (home and away) on top of each other, along with some other information that we can use to join back to the working set:
a UNION where two columns become one
Unified Teams Query Notes
Don’t forget to indent the inside of your CTE.
I used an alias on the column name for the first query of the UNION, but not the second. As you can see from the results below, the resulting table retains the column names from the first query, and one alias is not only enough, but it’s simpler and better looking (IMO, of course)

Home Team & Away Team -> Team
I used id as the column that we are going to use to join back onto the original working set. We cannot have any ambiguity in the join that we are building towards which means we cannot simply join on the date of the game because there are often more than one game per day. We would have to join on date AND another column, but what single column would we join on, since we’re unifying the teams on one side? The id, by virtue of the fact that every row has a distinct id and every row is itself a distinct game, is in essence a game ID, and therefore is all we need to build our future join upon.
Let’s use this unified team table we have built to try and gather the relevant numbers to calculate the ranking factors. Let’s go up the list of those ranking factors and begin with goals scored.
After we turn the unified teams query into a CTE, what happens when we join it back into our working set?

Blue box is the unified teams CTE, Red box is what we get from joining to the working set CTE on ID
As you can see here, we can’t just pull a column out of the working set to get our goals scored measure, one column is home goals and the other is away goals. What do we want to read off of the working set columns as we go down our team column in the unified teams CTE (the blue box above)? Ideally, in the CASE WHEN the team is the same as the home team, THEN we count the home goals, ELSE, we count the away goals:
Goals Scored Query Notes
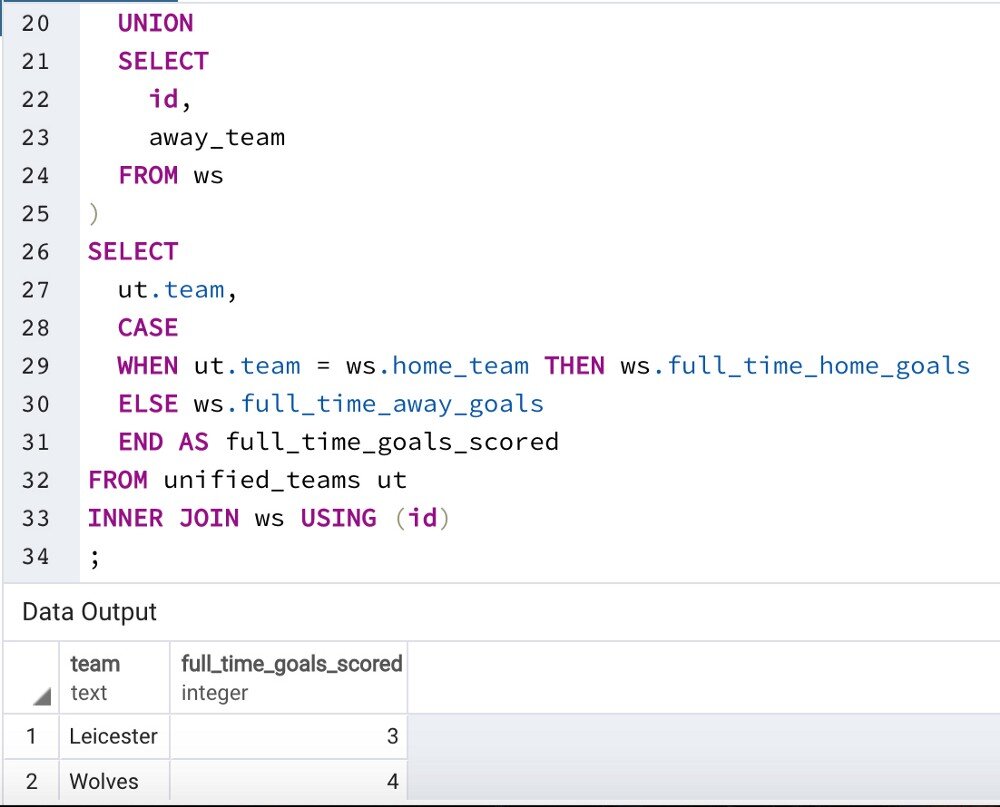
Don’t forget to indent the insides of your CTEs!
Give the CTEs (that aren’t the working set) a proper name, save the abbreviation for later on in the query, when you can turn it into an alias (unified_teams -> ut)
The CASE & the WHEN-THENs & the ELSE & the END AS of the statement all get their own lines, it looks good and it helps in the event you need to comment conditionals out as you’re exploring the data.
To calculate goal difference, we’ll have to add goals conceded to our query, but that is pretty straightforward, we just have to tweak what we already wrote ever so slightly so that when the team is home, we count away goals and vice versa:
Which gives us:

To calculate the points, we need to add three more columns: wins, draws and losses. We have the full_time_result column on the table, so we can read that to figure out what happened to the team on the day. (QUICK REMINDER OF HOW full_time_result works: H means home win, A means away win and D means dtraw)
Let’s concern ourselves with winning. An A or an H can be a victory, so we’re going to need to reflect that in our CASE statement:
Wins Query Notes

Indent the OR statement so it lines up with the overarching WHEN.
When your CASE statement runs more than one statement, it looks better to put the THEN on its own line as well.
I made the wins column an integer count of the wins (1 or 0) so we will be able to aggregate it as a SUM more easily later.
Using this template, it’s easy to build out draws and losses using the same logic and format we just used for wins with a couple of small tweaks:
Which finally gives us…

…everything we need!
Let’s quickly discuss the difference between the data we are using before and after the transform we do with this query we have built. The raw results data in our working set ws and then in xpert.england_view is broken out by game and is unique between one set of teams (home) and their opponents (away). The data from the transform query we have built is essentially ignorant of who the opponent is, it’s just aggregated results (soon-to-be aggregated results over time).
I would think it would be valuable to keep both of those tables in the database, but instead of a run of the mill view, I say we use a materialized view. The materialized view is essentially a table in the database, built using a query that is defined upon creation and is subsequently refreshed periodically. It is great in cases where you have a somewhat complex transform (check) that you think you will be querying often does not need to be updated that frequently (we’ll want to see the table every day, but it’ll only change every game day).
Let’s clean up our query a little bit, remove some stuff, add some things and get it ready to build our materialized view:
Materialized View Query Notes
Everything gets indented one last time, to be behind the CREATE statement.
I removed the working set CTE since we are no longer (only) concerned with the Wolves Leicester game.
I replaced references to the working set in two ways: first by replacing ws in the FROM statements to the actual view we are going to use, xpert.england_view and then I establish an alias for that view, xev, which I use to replace the references to ws in the SELECT statement.
I added game_date to our materialized view query, in case we want to build the table at any given date for some historical context, and then I ORDERed the table by the game_date and team. If we are actually going to use this table, ordering it properly will make it easier for the database to execute the query (not as effective as putting in an index, but we’ll save that for later).
QA!
This whole exercise was an attempt to figure out an easier way to build the Premier League table. Logically, it follows that for this whole endeavor to be viewed as successful, we should have a pretty straightforward way to query what we have built to conjure the standings. So that should be our QA, do we accurately build the table as it stands today, (reminder: today is February 12th, 2019).
Goals Scored, Goal Difference and Points
AND NOW THE MOMENT OF TRUTH:

Blue is from our query up there and red comes from the league table generator at 11x11
By jove, I think we have got it! We took our results data and used it to accurately construct the Premier League standings. We can now feel comfortable to hand our QA query to whomever wishes to know how the sports are going, and we can get outta here and enjoy our well-earned beer!
Structured Beer-y Language
Getting these standings was the first thing I really wanted to do when I was a fledgling data-dude, and, as I mentioned at the end of our first edition of the Sporting Stylish SQL series, it took me an unfortunately long time to make the leap from what I had in front of me (12xpert’s data) to what I wanted given to me, unable to fathom building it for myself.
Only a couple of notes on the table at this point, a couple of good stories happening on opposite sides of the table:
This was the game week that Manchester City took the lead from Liverpool, a lead they would not relinquish. Still kind of amazing the Reds could lose only one game for a whole season and still not win the league, but sovereign wealth funds are hard things to contend with, even for the likes FSG and Lebron James.
Newcastle claws above Cardiff and out of the relegation zone, (or as Rog of the Men in Blazers like to call it, “the Premier League moon door”), managing to stay in the Prem at the end of the season, despite having maybe the worst owner in all of professional sports (nsfw).




Create a View in PostgreSQL to Remove Duplicate Data
Part 2 of x of Sporting Stylish SQL with Stephen
Note: this was published originally on Medium in August 2019
Quick note at the top: it turns out that when we created and filled our table, I forgot to mention that we were also collectively going back in time ever so slightly to February 9th, 2019. Happy National Pizza Day!
So here’s where we stand so far: we’ve created a table, xpert.england, where every row is a game in the English Premier League, but since, as we now know, it’s “currently” the middle of the season, as we go forward there are going to be more CSVs with even more games. Here’s the rub though, these CSVs are also going to contain the data for the games we have already input, which means we are now faced with a dreaded burden of the data base: duplicate data. So how do we address this looming specter of duplication? Let me count some ways:
Edit the CSV itself by removing the rows which you already have in the DB. risk accidentally mutilating the data
Truncate (aka delete everything inside) the table before you upload a new CSV.
Upload the full CSV to the table every time, and use a View to weed out duplicate rows.
When it comes to making a decision on which option to go here, an important question to ask is: are we going to have to do this re-upload over and over again or is this an ad hoc, one-and-done kind of project?
I spoke with our manager and she said we’re going to be uploading this file after every game day, thus we are going to have to pick the option most suitable for setting up a reproducible process.
So, right off the bat, for me, Option 1 is a loser. It requires editing the data file and anytime you edit something you run the risk of, for lack of a better word, mutilating it somehow. Not to mention that it’s an extra step, external to the database, and would have to be done manually by someone. This sounds like just a hassle for us to QA and for whomever has to clean out those dupes (assuming that job doesn’t also fall to us, in which case it’s all just the one big hassle).
Option 1 is off the island, we’re left with Options 2 and 3. Both are good options, in that both can fairly easily be turned into set and forget processes. Option 2 (Truncating before uploading) could be set up with a trigger function which is a little more work but which would save storage space in your DB. Option 3 (Using a SQL View) is pretty simple to write and light on the database, the only downside, really, is that when push comes to shove, you have to remember to query the view and not the table (the table being full of duplicate data).
I will bet you have guessed by now that my preferred option is number 3 (it’s the title of the piece for Pete’s sake). It’s easy like I said, and it doesn’t tax the DB very much if at all. And if we do it right we get the added bonus of obviating the need for SQL updates while fixing errors or affecting changes in the scores (if you don’t think scores can change after the fact, think again).
If that updating part sounds a little confusing, don’t worry for now, we’ll come back to it when we run our QA.
Now we have been informed that a new CSV has been uploaded to the table, let’s open up pgAdmin and take a look at one game in particular, I’ll pick Tottenham at Everton. Let’s build that query together. Let’s look at the whole table for wherever the home team is Everton and the away team is Tottenham.
You see here that I begin the WHERE clause with the statement “1 = 1”. I do this so all my WHERE statements get their own line and begin with AND, which keeps them lined up and more easy on the eye than
```sql WHERE home_team = 'Everton' AND away_team = 'Tottenham' ```
It also allows me to comment out a WHERE condition out if I want to poke around the data a little bit without having to add any more ANDs.
Now what do we get when we put our lovely little query into pgAdmin?
Dupe-town
Above we can see a duplicate row that has been copied into the table in a subsequent upload, and we can also see the key (wink!) we need to tracking down the most recent upload. Since the id, the primary key, is constantly incrementing, it’s guaranteed to be higher for the new row, thus if we pick the version of the row with the highest (or MAXimum) id, it will be the most recently uploaded version of the row. And before you say it, yes, the created_at column would also tell us which was uploaded more recently, but it is a bit simpler for the processor to find a larger number than a later date.

Judiciously commenting out lines (as I did on line 2) is super effective in exploring your data,
but be wary of cluttering up your query and losing the plot
So now that we know we are going to use the id column to narrow down the rows from the most recent upload, we have to make a decision about what columns we use to define the data we are looking for. This question boils down to what do we presume about what are the columns in the data that should stay constant and which ones can possibly be variable. In our case let’s agree that the date the game took place and the teams involved will not change, even if the other particulars of the game (i.e. the final score) may. So it follows that game_date, home_team and away_team will be our mainstays, we’ll call them our constant columns.
Now how do we use these constant columns to create our view? Well the query we have been building is only aiming at one game, so lets see what introducing our constant columns into our query gets us.

Now you will notice that I added a GROUP BY statement at the bottom, allow me to explain. The MAX is what’s called an aggregate function, which means if you call it along with other columns, you have to indicate how & in what order you will be doing the aggregating; in our case, we have an arbitrary ordering of all of our constant columns.
Now that we have a way to pick our last rows, all we have to do is pick only those last rows. I am going to do that by turning the query we have built so far into a CTE and then joining it back to the table with an INNER JOIN so they are the only rows we get.
INNER JOIN on the last rows CTE so we only get the most recent upload
You see for our CTE version of our query, we no longer have the constant columns in the SELECT section, because once we have it in the GROUP BY, putting it in the SELECT becomes superfluous and indeed actually slows the query slightly. The INNER JOIN ensures that we only get those last rows we found with the CTE, thus we have found the most recent uploaded row for every game, i.e we have DE-DUPED this bad boy!
Now that we have the query we are going to use, let’s build that View!
QA!
Once we build this view, we have to make sure it works properly, which means creating a query that confirms the view is doing what it purports to be doing, which is displaying the most recently updated game data. Taking that into account, we have two things we have to assess:
The row counts line up.
If we change the CSV and then upload it, that change is reflected in the view.
The easiest way to see if the data in the CSV that has most recently been uploaded are the only data in the view is to count the number of rows in the CSV, and compare that with the number of rows in the table and the view.
Let’s build a single query that can check the number of rows in both the view and the table. We can join them on id, since that is the basis for the view anyway.
Now we just need to know our row counts so we know what we are looking to confirm. The most recent CSV has 261 rows, which added to the 258 we uploaded when we built the table should come to 519 rows total.
Drum roll, please.

t for Table ; v for View
We see that the duplicate rows from the table are not visible to the view. Now let’s see about changing scores:
Let’s say you are a die-hard Liverpool fan and you just hate the idea of Manchester City winning their game in hand here. Well, since we are just doing some QA, let’s rewrite the tale and edit the table such that Chelsea don’t just absolutely capitulate to City and the score is a much more respectable (sadly) 0–0 draw:

GRIM REALITY
BECOMES

After we upload our conspicuously (though not ostentatiously) edited CSV, we should see our new ‘reality’ reflected in our view.

Dispatches from the Reddest timeline
Our view has successfully removed duplicates and updated the score as we hoped, we have done what we set out to do which means we are done with QA. Let’s make sure we upload the uncorrupted (yeah I said it) data to make everything copacetic, and then it’s time for a beer!
Structured Beer-y Language
After finishing a project, I like to unwind and chat with my coworkers over a beer. This time we’re talking soccer highlight videos and Mariah Carey covers:
What a shellacking City gave Chelsea in that game, huh? It was actually difficult to find a suitably short highlight video, the rest were just at least 6 minutes of techno-backed schadenfreude which would have been too much to bear.
Also, I don’t know if you clicked on that Mariah Carey link above, but I had totally forgotten about the carnival-themed video with the weird clown intro, the roller blades and the singing-while-in-the-front-row-of-a-gd-rollercoaster. And to be perfectly honest, while I love that track and many other Mariah hits, my favorite rendition of that song, for which you did not ask, is this one by Owen Pallett.
Create a table in PostgreSQL out of a CSV using Atom and psql
The Premier (League) Edition
Welcome to the next fixture in our Sporting Stylish SQL with Stephen series. This edition is about using some of the tools we outlined last time to more efficiently (read: quickly) create SQL tables on demand.
Part 1 of x of Sporting Stylish SQL with Stephen
Note: this was published originally on Medium in August 2019
(and put behind the paywall shortly thereafter, but no worries, this is a friend link)
The Premier (League) Edition
Welcome to the next fixture in our Sporting Stylish SQL with Stephen series. This edition is about using some of the tools we outlined last time to more efficiently (read: quickly) create SQL tables on demand.
When it comes to the myriad of documents used to communicate data, Comma Separated Variable files or CSVs are almost definitely one of the easiest ways to interact with a SQL database. (Since the data within have to adhere to a very strict structure, they interface easily with Structured aka Relational Databases).
Pure text, no formatting, every dividing line in the row becomes a comma and every row ends when the commas stop. It is so effective in its simplicity as to be ubiquitous, thus you may find need at some point to take the column names off an exemplar CSV file and out of its contents create a SQL table into which you upload those CSVs. Doing so is straightforward but can be quite tedious, a tedium which I will to assuage with some shortcuts I have found along the way.
CSV as seen on Google Sheets
OR PUT ANOTHER WAY:
Date,HomeTeam,AwayTeam,FTHG,FTAG,FTR,HTHG,HTAG,HTR
2018-08-10,Man United,Leicester,2,1,H,1,0,H
2018-08-11,Bournemouth,Cardiff,2,0,H,1,0,H
2018-08-11,Fulham,CrystalPalace,0,2,A,0,1,A
2018-08-11,Huddersfield,Chelsea,0,3,A,0,2,A
2018-08-11,Newcastle,Tottenham,1,2,A,1,2,A
So let’s say our manager comes to us with this (part of a) CSV (here’s the real thing if you want to follow along)
She wants us to create a table in our PostgreSQL database into which we can pour the contents of CSVs so we can track the progress of the Premier League this season. To do this, we are going to create a SQL file that will:
Create a schema to house the table that houses the data
Create a table that houses the data (we’ll actually be creating an empty table and altering it by adding the columns on individually and sequentially)
Fill the table up by copying the contents of our provided CSV
Copy and Paste
First step: we take the column names directly off the CSV and copy them into a new document.
Command + C >> Command + V
Up- and (more pertinent) Downcasing
Next we use Atom’s downcasing functionality (command + K + L) to make all the terms lower case. Remember the capitalization: In SQL, Reserved words are upper case(e.g CREATE, INSERT, SELECT, etc.), and anything we name ourselves (schemas, tables, columns, etc.) are lower case.
Command + K + L
Now we are going to edit the column names so they’re easier to read and understand.
date,hometeam,awayteam,fthg,ftag,ftr,hthg,htag,htr
BECOMES
game_date,home_team,away_team,full_time_home_goals, full_time_away_goals,full_time_result,half_time_home_goals, half_time_away_goals, half_time_result
We can’t use the word date as a column name because DATE is a datatype and thus a reserved word, so we have to change that to something simple yet descriptive: game_date. For the rest of the values, I expanded their acronyms to make the more descriptive (and longer) column names so we could more easily understand and use the table after it’s created.
Now Copy and Paste those into a lower line and put them in parentheses. [note: if you highlight the line in Atom and press (, it will automatically put the highlighted portion into the parentheses for you]
game_date,home_team,away_team,full_time_home_goals, full_time_away_goals,full_time_result,half_time_home_goals, half_time_away_goals,half_time_result(game_date,home_team,away_team,full_time_home_goals, full_time_away_goals,full_time_result,half_time_home_goals, half_time_away_goals,half_time_result)
[another note: this part of the process may appear repetitive and asinine, but trust me it will pay off later]
Fancy Find and Replace
This next step is a little tricky, but let’s go through it step by step:
Highlight the top line with the header names
Press command + F to open the Find and Replace tool
Select the Use Regex and Only in Selection buttons on the tool
In the Find line, put a comma “,”
In the replace line put “\n” [Signifies a new line]
Hit Replace All.
Command + F
Excellent! We’ve successfully found and replaced all the commas in our selections with new lines!
We’ve (finally) arrived at a place where we get to add some SQL statements. And in addition to the columns we’ve gotten from the CSV, I’m going to add a couple of basic but dutiful columns to make our table more useable and performant:
id: this column just puts the row number on the row in the order in which it was created, thereby creating a value that is guaranteed to be unique across row to row, and is therefore a perfect candidate for a primary key.
created_at: this column records the time (according to the time zone to which your DB is set) that the row was created.
CREATE SCHEMA xpert; # SCHEMA TO HOUSE TABLE CREATE TABLE xpert.england(); # TABLE TO HOUSE DATA id # ROW COUNTER AND THUS PRIMARY KEY created_at # RECORD OF FILE UPLOAD TIME game_date home_team away_team full_time_home_goals full_time_away_goals full_time_result half_time_home_goals half_time_away_goals half_time_result (game_date,home_team,away_team,full_time_home_goals,full_time_away_goals,full_time_result,half_time_home_goals,half_time_away_goals,half_time_result)
Note: the schema is called xpert in deference to 12xpert, aka Joseph Buchdal, a betting analyst in the UK who keeps and maintains historical and current results along with betting data, of which the CSV we’re using is a small and pruned subset.
Multi-Cursor
We now have our columns lined up, but we have some commands to add to all those lines.
Highlight your newly vertical column names (but not the line in the parentheses) and press Command + Shift + L.
Now that we have all those cursors, we can easily type out the necessary statements we need to turn these names into commands. On the left of the name, you put in the ALTER statements:
ALTER TABLE xpert.england ADD COLUMN
And on the right put a space and a semicolon (;). Semi-colons signify the end of the SQL command, and the space we need so we can finish the statements with the datatype of each column.
Command + Shift + L
We are going to use the multi-cursor again for identifying the column types, but instead of selecting all those rows, we simply hold the command button down and click the mouse exactly where we want our other cursors to go.
Command + [[Mouse Click]]
Once we have all the datatypes properly placed, we have the frame of the table set up, now we just need to get in its contents. We can use PostgreSQL’s \copy utility, which can shuttle data in and out of your database.
A note on why we have all those column names in parentheses on the bottom of this file: the \copy command doesn’t need the column name of the table you are using unless some of the columns on the table are not on the CSV. I’m sure you remember when we added the id and created_at columns onto the table, well the CSV doesn’t have those. To successfully copy in the data in that case is to put all the column names you plan to insert your table in between parentheses, separated by commas of course. [I told you it would pay off]
```SQL CREATE SCHEMA xpert; CREATE TABLE xpert.england(); ALTER TABLE xpert.england ADD COLUMN id SERIAL PRIMARY KEY; ALTER TABLE xpert.england ADD COLUMN created_at TIMESTAMP NOT NULL DEFAULT NOW(); ALTER TABLE xpert.england ADD COLUMN game_date DATE; ALTER TABLE xpert.england ADD COLUMN home_team TEXT; ALTER TABLE xpert.england ADD COLUMN away_team TEXT; ALTER TABLE xpert.england ADD COLUMN full_time_home_goals INTEGER; ALTER TABLE xpert.england ADD COLUMN full_time_away_goals INTEGER; ALTER TABLE xpert.england ADD COLUMN full_time_result TEXT; ALTER TABLE xpert.england ADD COLUMN half_time_home_goals INTEGER; ALTER TABLE xpert.england ADD COLUMN half_time_away_goals INTEGER; ALTER TABLE xpert.england ADD COLUMN half_time_result TEXT; \copy xpert.england (game_date,home_team,away_team,full_time_home_goals,full_time_away_goals,full_time_result,half_time_home_goals,half_time_away_goals,half_time_result) FROM <path_to_csv_file> CSV HEADER ```
Let’s ignore the <path_to_csv_file> for a moment, let’s concentrate on the CSV HEADER at the end: PostgreSQL needs you to tell it what kind of file to expect and whether it has a header or not, so it will know how to read the file and whether to treat the first row of data as column names or simply values.
Recall: psql is a simple tool which allows you to control your database from the command line on your terminal.
I’m not here to tell you how to structure your files, but I’m going to show you a really simple way to do it for this situation and you can tweak it as you please. I put the SQL file (named xpert_table_build.sql) in a folder dedicated to the project and the CSV file (named england_18_19.csv) in the same directory in a subfolder labeled data. After navigating to this project’s directory, the copy command should look like this:
```SQL \copy xpert.england (game_date,home_team,away_team,full_time_home_goals,full_time_away_goals,full_time_result,half_time_home_goals,half_time_away_goals,half_time_result) FROM data/england_18_19.csv CSV HEADER ```
Important to note that the <path_to_csv_file> is relative in case above, but it can be absolute if you prefer. Now we run psql from the project directory, and use the \i command, which is how you run SQL files in psql.

Table Creation with a little QA to boot
On the top there you see your CREATE & ALTER statements have successfully run, along with the COPY.
And as you can see, after the copy command, we have also run the all-important…
QA!
Whenever you build something, or do anything in your database really, you should run tests to confirm everything goes according to plan. In this case, we have to confirm the table built and filled successfully:
I ran psql’s describe command /d on the table to confirm the column structure conformed to our CSV file structure (it did).
I counted the number of rows to make sure that matched with how many rows in our CSV (316, it did).
And there you have it, a table you can fill with the CSVs and refill till kingdom come (or you run out of room in your DB). We’ll be querying this table in future editions of this series, but for now, it’s beer o’clock.
Structured Beer-y Language
After finishing a project, I like to unwind and chat with my coworkers over a beer. This time we’re talking searching for data with metaphorical blinders on and the general availability of data:
Once, early in my days of data devotion, I was flailing around the internet trying to find a downloadable version of the Premier League table. Woe was me when all I could find were these files with all the results of all the games, tracked over years. Since it was not exactly what I was looking for, I ignored it as I tried desperately to find my ideal dataset. SMDH.
Then I realized that not only was this better than the league table, this data would allow me to construct the league table at any date since 1993. Little did I know that this treasure trove of data was not only invaluable, it was meticulously updated and maintained and consistent and free and even provides half time scores, which is a paid feature of football-data.org. I have validated this data against multiple other sources time and again, and it’s accurate every time.
All this is to say we should appreciate the work people like 12xpert do, maintaining data sources like this one and allow others to use it free of charge. As I learned in those early days, data out in the world can often be harder to come by than you think, even more so if you let the perfect be the enemy of the good and ignore entirely the suitable, and indeed fruitful data like I did.
Sporting Stylish SQL with Stephen
Part 0 of x: An Introduction to the Sporting Stylish SQL with Stephen series where we build sports stuff with SQL
Note: this was published originally on Medium in July 2019
When I started using Structured Query Language in my job, it was a baptism by fire. I understood how SQL worked, but I had to figure a lot of things out on my own about its operational uses. I decided I had to learn by doing, and though I very much did not want to make a mess of the data my company was keeping, I did really want to learn how best to use the technology at my fingertips, to really stretch my wings. So I spun up a PostgreSQL database on my personal computer and started playing around with publicly available soccer data. I figured that one of the best ways to learn is to practice, and what better way to practice than to toy around with data you already understand. Having to really work to obtain the data and then to mold them into something from which you can actually gain insight makes the whole endeavor — dare I say it — actually kind of fun.
When dealing with modern business intelligence platforms, it behooves you to have a solid comprehension of SQL. Tableau has SQL features it uses (inner and left joins, unions, etc.), Looker generates SQL to run its queries and even if the tool you use is not itself explicitly SQL based, a lot of the most popular data bases and warehouses (e.g Amazon Redshift and Snowflake) are built to run SQL. Tableau was recently acquired by Salesforce, and Looker just recently announced that it is being integrated into Google Cloud; major players are betting big on this straightforward technology, so learning how to use it effectively is, to my mind, a no-brainer.
So from here on out, consider us, you the reader and I the author, coworkers on the same data analysis team. You are a new hire and have been paired up with me to create tables and run analyses in our SQL database. I will presume you have a basic knowledge of how SQL works, but I will also provide links to more in-depth explanations of some of the concepts we run through in this series.
But first, if we’re going to start working together, we should get to know each other. So here goes:
ALLOW ME TO INTRODUCE MYSELF
My name is Stephen, and I’ve been a Business Intelligence engineer for about five years. I have lived in the Bay Area for almost 15 years, I have an incredible wife, two terrific twin boys (pictured) and a Boston terrier (also pictured). I love movies, TV, math and, relevantly for this series, sports. I spend an inordinate amount of time following the ins-and-outs of European and world soccer and NBA Basketball, I just cannot get enough. I was a math major and soccer player in college, and taught myself a little Python, R and SQL programming after I got out of school, just enough to get a job at a startup out here. It was there that I learned the day-to-day of using SQL for data storage and analysis, and picked up some tips and tricks for getting stuff done quick-, clean-, effective- and efficiently. I am excited to share some of these tips with you, my esteemed and dutiful coworker, but before that, let’s lay some groundwork:
SOME TOOLS OF THE TRADE
Since I am driving in this particular pairing paradigm, I’m running everything on my computer, so here’s a rundown of what I will mostly be using:
A Macbook Pro (currently running Sierra), but most of the tools here are open source and for the better part also platform agnostic (as far as I know).
A local PostgreSQL server and database set up on my Macbook. Here’s a great tutorial on how to set that up on your own computer if you’re interested in following along. It’s fairly straightforward, only one thing you have to install first (a package manager called Homebrew, but the tutorial will walk you through all of that).
psql is a “a terminal based front-end to PostgreSQL”, allows you to access and query any PostgreSQL database (and indeed Redshift as well), local or remote as long as you have access to it.
pgAdmin is lovely, easy to use and free, just gets a lot of updates. psql is a great tool for running scripts and maybe a QA query, but its display is trash. If you’re going to run any kind of SELECT query, pgAdmin is industry standard. Other options are TablePlus (free) or Postico (unlimited free trial, comes with an upsell). To underline the difference between psql and pgAdmin, behold the same query in the screenshots below
psql, not hot
pgadmin, hot
If you’re not typing queries directly into psql or pgAdmin, you can write them out first into a SQL script and run the script using psql. The best way to write that script, and indeed many other types of text files, is a text editor. Atom is my text editor of choice, Sublime Text (currently on version 3) is a great alternative. If you’re not all that into using your mouse, you can try VIM, one of the oldest and most robust text editors that’s built right into your terminal, (not as intuitive as Atom or Sublime at first, but supposedly amazing once you get the hang of it and will give you a little cache amongst fellow engineers)
Finally, you should have some kind of spreadsheet software, Numbers is what I use on the Mac, essentially because I am too frugal to purchase Microsoft Office just to use Excel. Spreadsheet software can come in very handy in some cases, not just with data manipulation but also for data cleaning.
STARTING STYLE TIPS
Now we get to the nitty gritty.
I am a naturally forgetful person, and when I build a SQL query, I don’t want to have to remember everything about the construction of that query and the data underlying it. Instead, I would prefer that the query itself be written in a straightforward (hopefully elegant) way so as to communicate clearly what is being requested of the data.
Let’s go through some of the basics with an example query:
The query above lays out many but not all of the salient points, (no WHERE statement or GROUP BY, we’ll get to those later). The important things to note are these:
Capitalize the reserved words — anything that’s not a name or alias for something in the database goes in upper case.
Indent for the SELECT statement inside Common Table Expressions (CTEs, but not the bad kind). I prefer a tab size of two spaces, it makes everything else line up very elegantly, but to each their own.
Indent the column names and put them on a new line from the SELECT command.
FROM goes back (outdents) to the same margin on which the SELECT command lies.
The closed parenthesis that terminates the CTE gets its own line, even if there’s another CTE coming.
The line for a new CTE starts with a comma
UNION and INTERSECT commands get their own line.
Let’s stop there for now, we don’t want to overdo it on day one. It was nice introducing myself and onboarding you a little bit, I look forward to working together and hope we can help each other grow in our respective careers!
Now, if you want to join me for a bonus after work beer and chat, I am going to break down what this query is actually doing over a nice cold one. If you are over it and are uninterested in the nitty gritty, no worries, I’ll see you next time!
STRUCTURED BEER-Y LANGUAGE
This particular dataset is built off Basketball Reference’s advanced stats for Game 6 (the clincher) of the Warriors-Rockets series in the 2019 playoffs. Daryl Morey reportedly contends that you need three straight up stars to win a championship. So what I wanted to see was out of the top three players on both teams, who was the best player defensively in that cohort. I defined top three in this case by choosing the three players out on the floor for their respective teams the longest, and since the game was close, there were no garbage time fourth quarter minutes for the far side of the bench to eat up, i.e it should be that your best players are on the floor the longest) and for my defensive measure, I used points allowed per one hundred possessions (BR’s de facto defensive efficiency rating). The result:

I’m not crying you’re crying
Did I reverse engineer (contrive) an explanation for singling out Andre Iguodala; a player who also had the highest points made per 100 possessions amongst the top three Warriors during that game 6 which they won without KD; a player who shut down a 🐐contender to win Finals MVP (tbf I think Lebron should have won that award); a defense-first, level-headed, tone-setting vet who may have cemented his hall of fame candidacy as a sixth man; would I do that? Never.